SpringAI – Agentic Workflow Architecture
 Phần 2 – Agentic Workflow Architecture
Phần 2 – Agentic Workflow Architecture
 What: Workflow Architecture là gì?
What: Workflow Architecture là gì?
Không phải lúc nào cũng cần một agent có khả năng tự quyết định hoàn toàn.
Trong nhiều trường hợp, hệ thống chỉ cần điều phối LLM thực hiện một chuỗi bước cố định. Khi đó, ta không cần xây
dựng agent hoàn chỉnh mà chỉ cần triển khai theo mô hình workflow.
Hiểu đơn giản: workflow là cách đưa LLM vào hệ thống với luồng xử lý rõ ràng, do con người chủ động thiết kế và kiểm soát.
Ưu điểm & giới hạn của workflow
Việc triển khai LLM theo hướng workflow mang lại nhiều lợi thế thực tiễn, đặc biệt trong môi trường backend Java:
✅ Ưu điểm
- Dễ kiểm soát: Các bước xử lý được xác định rõ bằng code, dễ kiểm thử và debug.
- Tích hợp nhanh: Có thể đưa vào hệ thống hiện có mà không cần thay đổi kiến trúc tổng thể.
- Phù hợp với bài toán ổn định: Các use case như phân tích, tổng hợp, sinh báo cáo tuần tự rất phù hợp.
- Có thể mở rộng dần: Từng bước có thể thêm validator, gate, logging mà không ảnh hưởng toàn bộ pipeline.
⚠️ Một số giới hạn
- Thiếu linh hoạt trong xử lý ngữ cảnh: Workflow không duy trì memory hoặc trạng thái nếu không cài riêng.
- Không tối ưu cho yêu cầu thay đổi liên tục: Mọi nhánh xử lý đều cần code hóa rõ ràng, khó mở rộng theo ngữ cảnh.
- Khó thích ứng với luồng xử lý không đoán trước: Khi hành vi đầu vào quá đa dạng, workflow sẽ cần nhiều nhánh hard-code, dễ phình to và khó bảo trì.
Vì vậy, workflow rất phù hợp cho giai đoạn đầu triển khai – giúp kiểm soát tốt, đánh giá hiệu quả rõ ràng. Nhưng nếu bài toán về sau yêu cầu tính tự thích ứng cao, cần cân nhắc chuyển dần sang mô hình agent thực thụ.
Spring AI cung cấp sẵn các ví dụ để định nghĩa workflow một cách tường minh — bạn có thể kiểm soát từng bước gọi LLM, kết hợp với tool, lọc kết quả và đưa ra đầu ra cuối cùng.
 How: Các Workflow Architecture thường gặp trong agentic system
How: Các Workflow Architecture thường gặp trong agentic system
1. Chain-of-Prompts (Prompt Chaining)
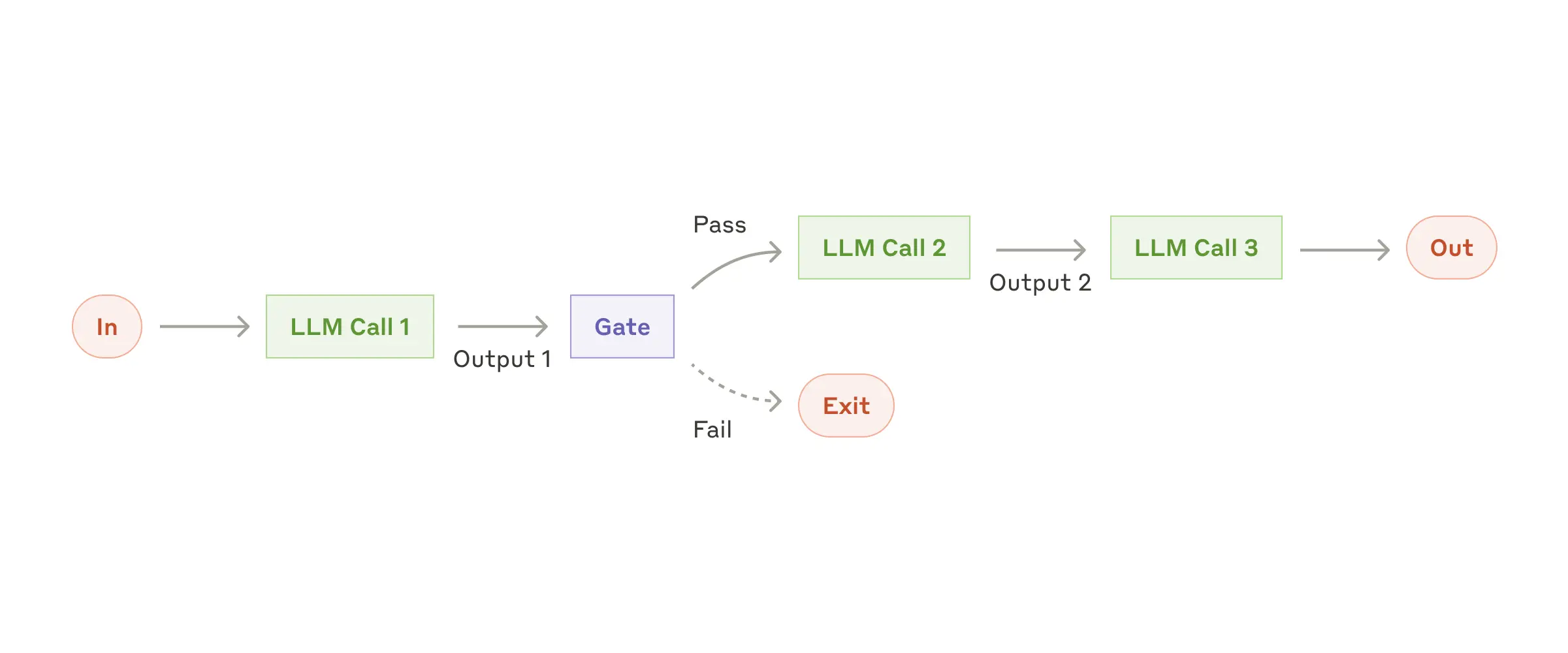
Đây là dạng workflow đơn giản và dễ kiểm soát nhất. Ý tưởng là chia một tác vụ lớn thành nhiều bước xử lý nhỏ, mỗi bước
là một prompt riêng biệt.
Đầu ra của bước trước sẽ là đầu vào của bước kế tiếp — tạo thành một chuỗi tuần tự.
Ứng dụng điển hình:
- Phân tích nội dung → tóm tắt → rút insight
- Tiền xử lý → chuẩn hóa dữ liệu → sinh báo cáo
Spring AI cũng cho phép chèn các bước kiểm tra trung gian (“gate”) sau từng prompt để xác nhận dữ liệu đầu ra đáp ứng yêu cầu trước khi chuyển tiếp.
| 📌 Khi nên dùng | ❗ Giới hạn tương ứng |
|---|---|
| Luồng xử lý đã được xác định rõ ràng từ trước | Khó thích ứng nếu cần rẽ nhánh, điều kiện xử lý động |
| Mỗi bước có thể mô tả riêng bằng prompt độc lập | Dễ lỗi dây chuyền nếu bước trước trả kết quả không đúng |
| Cần kiểm soát từng giai đoạn và dễ log/debug | Nếu chuỗi quá dài → khó kiểm soát, bảo trì phức tạp |
2. Routing
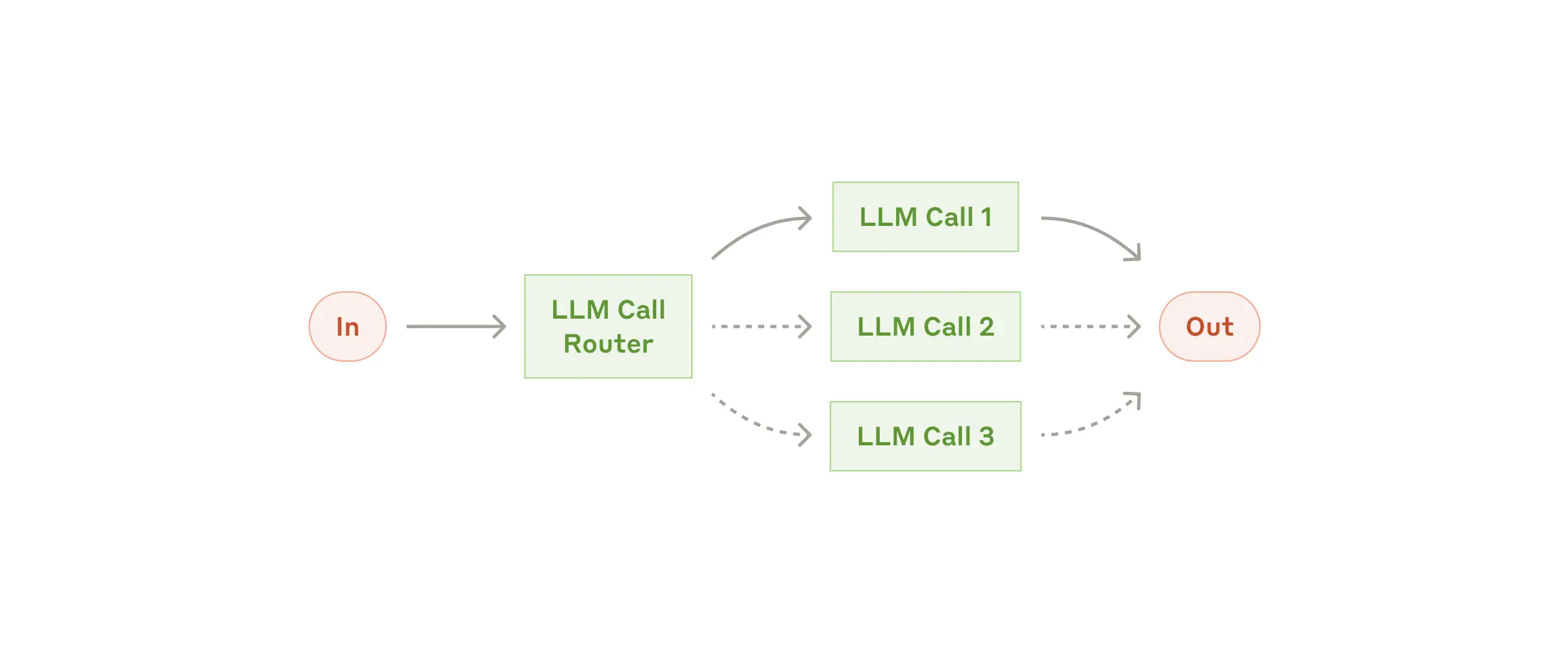
Thay vì xử lý tuần tự theo một chuỗi cố định, routing cho phép hệ thống phân loại đầu vào và điều hướng đến nhánh xử lý phù hợp. Mỗi loại yêu cầu (intent) sẽ được gán cho một logic riêng biệt.
Ví dụ:
- Người dùng hỏi về billing → chuyển đến flow xử lý thanh toán
- Người dùng hỏi về lỗi kỹ thuật → chuyển đến nhánh hỗ trợ kỹ thuật
Ứng dụng điển hình:
- Phân loại câu hỏi khách hàng
- Phân tích intent từ nội dung email / message / feedback
- Xử lý truy vấn API nhiều chức năng
| 📌 Khi nên dùng | ❗ Giới hạn tương ứng |
|---|---|
| Đầu vào đến từ nhiều mục đích khác nhau | Nếu logic phân loại không chính xác → dễ route sai |
| Mỗi mục đích yêu cầu xử lý riêng bằng prompt/tool | Khi số lượng nhánh lớn → logic phân nhánh trở nên phức tạp, khó bảo trì |
| Logic phân loại có thể xác định từ sớm (từ khóa, intent, metadata) | Không phù hợp nếu intent đầu vào không rõ ràng hoặc bị chồng lấn |
3. Parallel Execution (Sectioning / Voting)
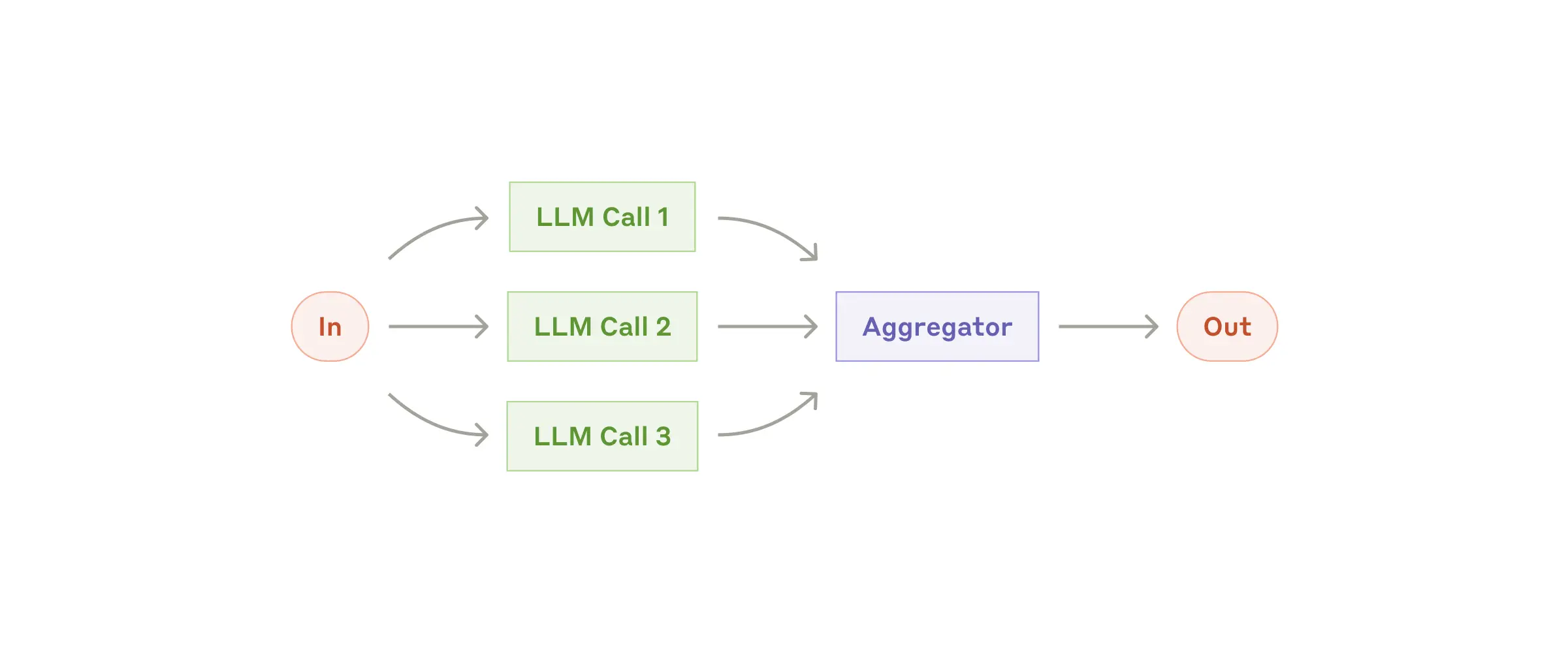
Với dạng workflow này, hệ thống sẽ chạy nhiều prompt đồng thời với cùng một đầu vào, sau đó tổng hợp hoặc chọn ra kết quả tốt nhất. Mục tiêu là tận dụng hiệu suất xử lý song song và tăng độ tin cậy của kết quả.
Ví dụ: Một yêu cầu phân tích có thể được xử lý đồng thời theo nhiều hướng (góc nhìn khách hàng, nhân viên, nhà đầu tư), sau đó gom lại thành báo cáo tổng hợp.
⚙️ Cách tổ chức
- Sectioning: Chia một nhiệm vụ lớn thành nhiều phần độc lập, mỗi phần xử lý bằng prompt riêng → gom kết quả lại.
- Voting: Chạy cùng một prompt nhiều lần → nếu nhiều kết quả trùng nhau → chọn ra kết quả ổn định nhất.
Ứng dụng điển hình:
- Phân tích cùng một dữ liệu từ nhiều góc nhìn (multi-perspective)
- Sinh nhiều bản nháp nội dung → chọn bản tốt nhất
- Rút insight từ các đoạn văn bản có cấu trúc giống nhau
| 📌 Khi nên dùng | ❗ Giới hạn tương ứng |
|---|---|
| Các phần của nhiệm vụ có thể xử lý độc lập, không phụ thuộc nhau | Không phù hợp nếu các phần cần chia sẻ ngữ cảnh hoặc dữ liệu |
| Cần kiểm tra tính ổn định bằng cách lặp nhiều lần (voting) | Cần cơ chế tổng hợp rõ ràng — nếu không sẽ gây nhiễu, khó chọn kết quả |
| Tốc độ quan trọng → xử lý song song tiết kiệm thời gian | Tiêu tốn nhiều tài nguyên hơn (gọi nhiều LLM cùng lúc) |
4. Orchestrator – Workers
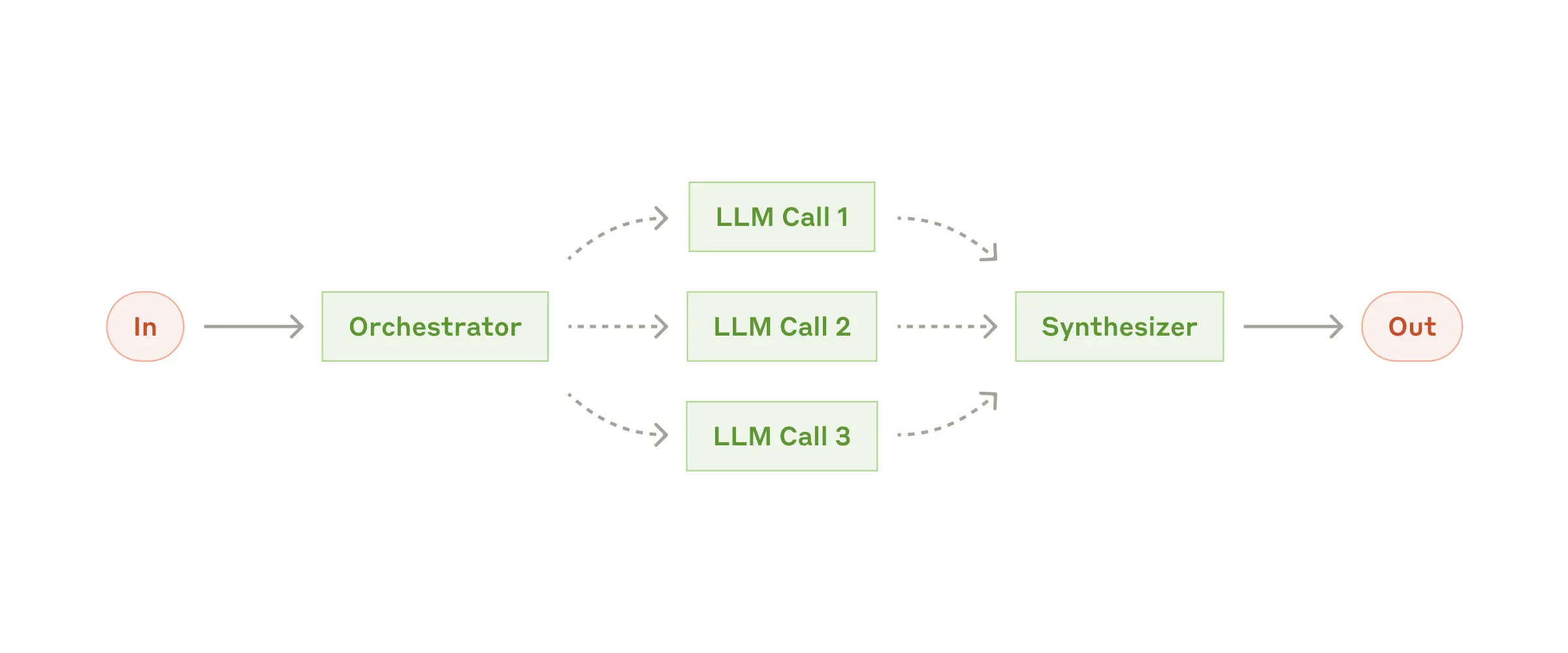
Mô hình này tách riêng vai trò điều phối (orchestrator) và xử lý (worker). LLM trung tâm sẽ tiếp nhận yêu cầu đầu vào, * *phân tích và chia nhỏ nhiệm vụ thành các phần độc lập**, giao cho các “worker” xử lý riêng lẻ. Sau đó tổng hợp kết quả và đưa ra đầu ra hoàn chỉnh.
Ví dụ: Nhận yêu cầu “soạn tài liệu kỹ thuật”, orchestrator chia thành: mô tả API → hướng dẫn sử dụng → ví dụ mã nguồn → worker xử lý từng phần → orchestrator ráp lại thành file hoàn chỉnh.
⚙️ Cách tổ chức
- Orchestrator: LLM trung tâm – tiếp nhận yêu cầu, phân tích mục tiêu và chia task
- Workers: Các thành phần xử lý từng task nhỏ theo prompt riêng biệt
- Tổng hợp: Orchestrator thu kết quả từ worker, sắp xếp lại và xuất ra kết quả cuối
Ứng dụng điển hình:
- Sinh tài liệu kỹ thuật từ nhiều phần nhỏ (API, hướng dẫn, ví dụ)
- Viết báo cáo đa phần (mở bài, phân tích dữ liệu, đề xuất hành động)
- Phân tích yêu cầu dự án → chia task cho dev, tester, PM,… (định hướng AI planning)
| 📌 Khi nên dùng | ❗ Giới hạn tương ứng |
|---|---|
| Bài toán đủ lớn và có thể chia nhỏ thành các phần xử lý độc lập | Cần xác định rõ cách phân task — nếu không sẽ bị thiếu sót logic |
| Muốn tách riêng bước “lập kế hoạch” và “thực thi” | Kết quả từ worker có thể lệch nhau → cần logic ráp nối, hợp nhất tốt |
| Cần mở rộng linh hoạt (thêm worker mà không ảnh hưởng toàn hệ thống) | Dễ phát sinh worker dư thừa hoặc thiếu đồng bộ nếu orchestrator thiếu kiểm soát |
5. Evaluator – Optimizer
<img src=”/assets/imgs/evaluator-workflow.png” alt=”” width=”100%” height=/>
Thay vì chấp nhận ngay kết quả đầu tiên mà LLM sinh ra, workflow này bổ sung một bước đánh giá (evaluate) để kiểm tra chất lượng đầu ra. Nếu kết quả chưa đạt yêu cầu, hệ thống sẽ tự động tối ưu lại (optimize) và thử lại.
Ví dụ: Yêu cầu viết email – nếu câu trả lời chưa đủ lịch sự, evaluator phát hiện và yêu cầu LLM chỉnh sửa → đến khi đạt yêu cầu mới trả kết quả ra ngoài.
⚙️ Cách tổ chức
- Generator: Sinh kết quả ban đầu từ prompt
- Evaluator: Kiểm tra chất lượng đầu ra theo tiêu chí đặt sẵn
- Optimizer (tùy chọn): Nếu đánh giá không đạt → tạo prompt phản hồi để cải thiện đầu ra → lặp lại
Ứng dụng điển hình:
- Sinh email, văn bản, nội dung cần tuân thủ tone giọng và phong cách
- Sinh đoạn mã cần kiểm tra đúng format, đầy đủ đầu vào/đầu ra
- Bài toán cần loop cải tiến nhiều lần để đạt độ “đủ tốt”
| 📌 Khi nên dùng | ❗ Giới hạn tương ứng |
|---|---|
| Bài toán yêu cầu đầu ra đúng tiêu chuẩn, khó chấp nhận lỗi | Nếu tiêu chí đánh giá mơ hồ → evaluator dễ đánh giá sai |
| Cần khả năng tự cải thiện đầu ra qua nhiều vòng phản hồi | Lặp quá nhiều vòng có thể làm tăng chi phí và độ trễ xử lý |
| Muốn tách rõ giữa bước “sinh kết quả” và bước “đánh giá chất lượng” | Không phải bài toán nào cũng dễ xác định tiêu chí đánh giá cụ thể |
🧩 Tổng kết: Workflow – Làm tốt phần cơ bản, nhưng chưa đủ nếu bài toán phức tạp
Triển khai theo workflow là cách rõ ràng và dễ kiểm soát nhất khi tích hợp AI vào hệ thống backend hiện tại. Logic được viết bằng code, từng bước có thể test riêng, dễ debug và log.
Nhưng nếu bắt đầu áp dụng vào các bài toán cần xử lý linh hoạt hơn, workflow sẽ đụng trần.
| ✅ Điểm mạnh | ⚠️ Giới hạn tương ứng |
|---|---|
| Logic xử lý rõ ràng, dễ test/log | Không phù hợp với các luồng xử lý khó đoán trước |
| Dễ tích hợp vào hệ thống Java đang dùng | Thiếu khả năng nhớ – không duy trì được ngữ cảnh |
| Từng bước được code sẵn → dễ bảo trì | Không tự điều chỉnh nếu output không đúng – phải tự xử lý trong code |
| Có thể chia nhỏ để làm từng phần độc lập | Không chủ động được – luôn phải đi theo flow cố định |
| Có thể kết hợp nhiều workflow lại với nhau (routing → parallel → eval…) | Dễ phình to và khó debug nếu không có cấu trúc rõ ràng khi ghép nối |
Những giới hạn này không phải điểm yếu – mà là ngưỡng tự nhiên của workflow, khi hệ thống bắt đầu cần tính linh hoạt cao hơn.
📌 Nếu công việc hiện tại đang ổn với workflow, tiếp tục khai thác là hợp lý.
📌 Nhưng nếu bắt đầu xuất hiện bài toán cần xử lý theo ngữ cảnh, phản hồi theo kết quả đầu ra, hoặc tự gọi tool phù hợp —
thì có lẽ đã đến lúc cân nhắc mô hình Agent thực thụ.
👉 Phần tiếp theo sẽ trình bày rõ kiến trúc Agent, nơi LLM có thể tự chọn bước tiếp theo, tự gọi tool, và xử lý linh hoạt hơn mà không phải viết sẵn mọi tình huống.