Knowledge: LLM-based Multi-Agents (LLM-MA): Tổng quan, Kiến trúc và Hướng nghiên cứu
LLM-based Multi-Agents (LLM-MA): Tổng quan, Kiến trúc và Hướng nghiên cứu
1. Introduction (Mở đầu)
LLM-based Multi-Agents (LLM-MA) là cách tổ chức nhiều agents chuyên vai phối hợp để giải quyết các bài toán phức tạp tốt hơn một agent đơn lẻ. Thay vì “một mô hình làm tất cả”, LLM-MA chuyên môn hóa (specialize) thành các agents khác nhau và cho phép chúng tương tác (trao đổi, tranh biện, phối hợp) trong một môi trường xác định. Kết quả: hệ thống đạt trí tuệ tập thể (collective intelligence), tăng tính chính xác, khả năng bao phủ và thích nghi liên tục.
Nhiều nghiên cứu báo cáo kết quả khả quan trong: phát triển phần mềm, hệ đa robot, mô phỏng xã hội/chính sách, và game. Tuy nhiên, bức tranh vẫn rời rạc. Bài viết này tổng hợp có hệ thống và “giải phẫu” LLM-MA theo bốn trụ cột cốt lõi, đồng thời nêu ứng dụng, bộ dữ liệu/benchmark, và thách thức – cơ hội tiếp theo.
2. Background & Motivation (Bối cảnh & Động lực)
- Giới hạn của single-agent: kiến thức tĩnh, khó tự kiểm lỗi, khó bao phủ đa kỹ năng và bối cảnh phong phú.
-
Lợi thế của LLM-MA:
- Specialization: mỗi agent tập trung một vai trò (PM, Architect, Dev, Reviewer… hoặc người chơi/giám khảo trong game, proponent/opponent trong debate).
- Coordination: agents giao tiếp và phối hợp (hợp tác, tranh biện, cạnh tranh) để tự kiểm tra chéo và tối ưu lời giải.
- Learning-loop: tận dụng feedback (từ môi trường, từ agents khác, từ con người) + memory + self-evolution để cải thiện theo thời gian.
3. Dissecting LLM-MA Systems: Interface, Profiling, Communication, and Capabilities
Phần này “giải phẫu” hệ LLM-MA qua bốn trụ cột: Agents–Environment Interface, Agents Profiling, Agents Communication, và Agents Capabilities Acquisition.
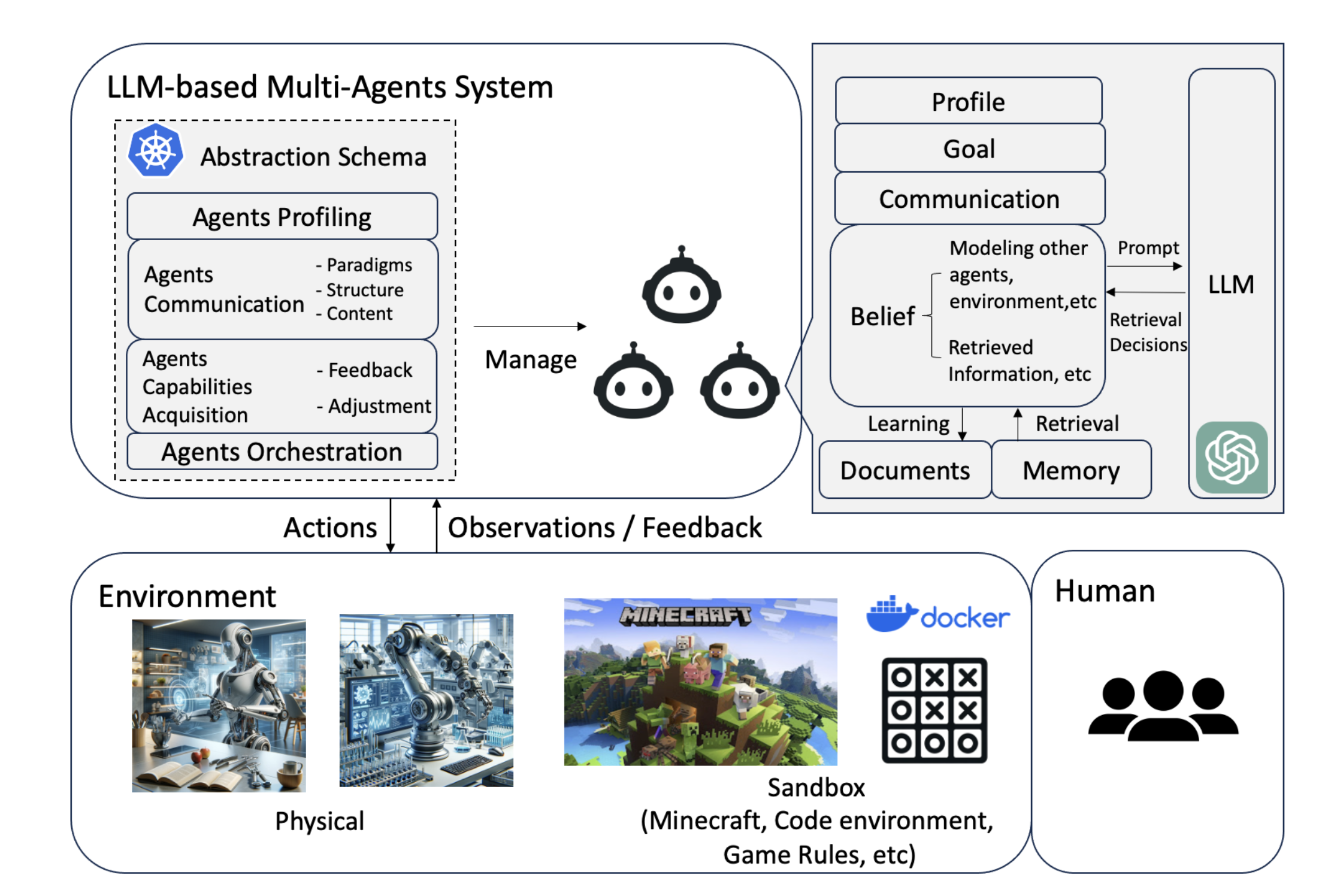
3.1 Agents–Environment Interface (Môi trường & Cách tương tác)
Khái niệm: Môi trường vận hành quyết định quan sát → hành động → phản hồi của agents, từ đó định hình hành vi và cách ra quyết định.
Ba loại kiểu môi trường:
-
Sandbox – môi trường mô phỏng/ảo do con người dựng
- Cho phép thử nghiệm chiến lược, giới hạn rủi ro.
- Ví dụ: code interpreter trong dev; luật chơi trong game.
- Minh họa: Werewolf – sandbox đặt khung ngày/đêm, thảo luận, bỏ phiếu; các agents (Seer, Werewolves…) hành động, nhận phản hồi trạng thái, điều chỉnh chiến lược theo diễn tiến.
-
Physical – môi trường thế giới thực
- Agents (đặc biệt robot) tuân theo ràng buộc vật lý; hành động có hệ quả trực tiếp.
- Ví dụ: quét sàn, đóng gói, sắp tủ → quan sát–hành động–nhận phản hồi lặp để tăng tay nghề.
-
None – không có môi trường bên ngoài
- Trọng tâm là giao tiếp nội bộ giữa agents (tranh biện, hội ý) để đi đến kết luận/đồng thuận.
- Ví dụ: nhiều agents tranh luận một câu hỏi học thuật để tinh luyện đáp án.
3.2 Agents Profiling (Định nghĩa & Xây hồ sơ)
Mục tiêu: Đặt khung vai cho mỗi agent: đặc điểm, kỹ năng, hành vi, ràng buộc, tiêu chí đầu ra. Profiling là kim chỉ nam cho phối hợp và đánh giá hiệu quả.
Ví dụ theo miền:
- Game: người chơi với vai/skill khác nhau, đóng góp khác nhau vào mục tiêu.
- Software development: PM/Engineer/Reviewer/QA với trách nhiệm & chuyên môn rõ.
- Debate: proponent/opponent/judge với chiến lược và tiêu chí riêng.
Ba phương pháp lập hồ sơ:
- Pre-defined – do nhà thiết kế hệ thống định sẵn (rõ, kiểm soát tốt).
- Model-Generated – để LLM sinh profile theo ràng buộc/mục tiêu (linh hoạt, nhanh).
- Data-Derived – suy xuất từ dữ liệu/bộ mẫu có sẵn (nhật ký, hồ sơ điển hình).
3.3 Agents Communication (Mô hình – Cấu trúc – Nội dung)
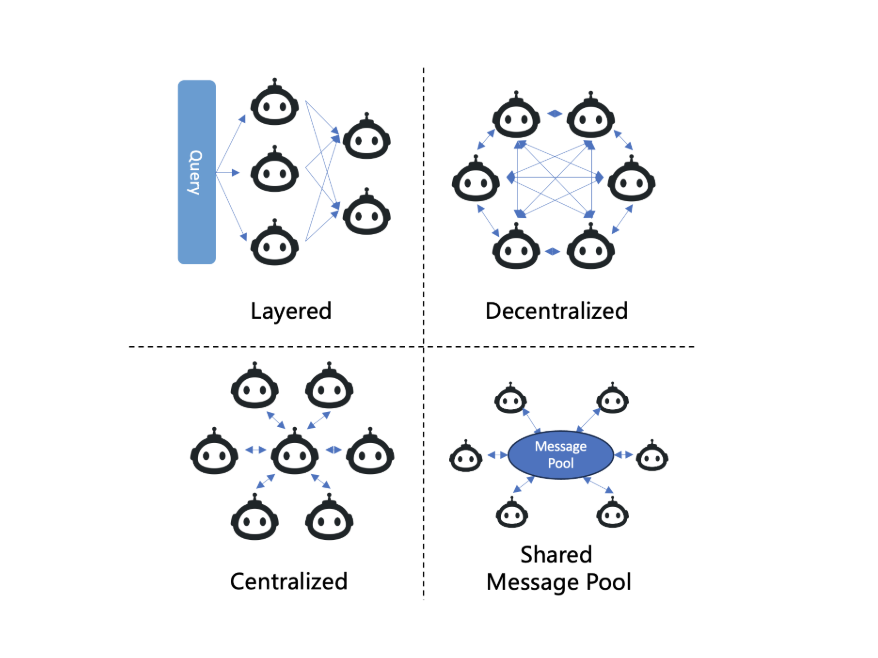
Paradigms (mô hình giao tiếp):
- Cooperative: hợp tác vì mục tiêu chung; chia sẻ tri thức để nâng chất lượng lời giải.
- Debate: tranh biện, phản biện qua lại để tinh luyện hoặc đạt đồng thuận.
- Competitive: mục tiêu có thể xung đột; thúc đẩy khám phá không gian lời giải.
Structures (cấu trúc giao tiếp):
- Centralized: một/nhiều agent trung tâm điều phối, các agent khác kết nối qua nút trung tâm.
- Layered (phân lớp, kiểu DyLAN): phân cấp; có thể chọn agent lúc suy luận và early-stopping.
- Decentralized (peer-to-peer): agents nói chuyện trực tiếp; thường dùng trong mô phỏng thế giới.
- Shared Message Pool (kiểu MetaGPT): kho thông điệp dùng chung publish/subscribe theo profile để giảm nhiễu, tăng hiệu suất.
Content (nội dung giao tiếp):
- Chủ yếu văn bản: mã nguồn, nhận định, giả thuyết, chiến lược… tùy ứng dụng.
3.4 Agents Capabilities Acquisition (Tiếp thu năng lực)
Nguồn Feedback (đầu vào để học):
- Environment: thực hoặc mô phỏng (dev: code interpreter; robot: cảm biến).
- Agents Interactions: đánh giá/phản hồi lẫn nhau từ hội thoại/nhật ký giao tiếp.
- Human Feedback: căn chỉnh theo giá trị/ưu tiên con người (human-in-the-loop).
- None: một số mô phỏng chỉ phân tích kết quả, không cấp feedback cho agents.
Cách agents tự nâng cấp:
- Memory: lưu & truy hồi ký ức liên quan (đặc biệt các tiền lệ thành công) để điều chỉnh hành vi hiện tại.
- Self-Evolution: tự biến đổi mục tiêu/chiến lược, tự rèn dựa trên feedback/log giao tiếp (ví dụ ProAgent dự đoán đồng đội để điều chỉnh; LTC – Learning through Communication biến communication logs thành dữ liệu huấn luyện/fine-tune → thích nghi liên tục).
- Dynamic Generation: hệ có thể sinh agents mới on-the-fly theo nhu cầu để mở rộng/giải nút thắt.
4. Implementation Tools and Resources (Công cụ & Tài nguyên triển khai)
4.1 Multi-Agents Framework (Các framework mã nguồn mở)
Ba framework tiêu biểu cho xây dựng hệ thống multi-agents dựa trên LLM:
-
MetaGPT (Hong et al., 2023):
Áp dụng nguyên lý assembly line (dây chuyền lắp ráp), chia vai trò rõ ràng cho từng agent theo quy trình SOP (Standard Operating Procedures). Nhờ đó, giảm hallucination trong các tác vụ phức tạp. Phù hợp với mô hình hoá quy trình công việc thật. -
CAMEL (Li et al., 2023b):
Framework hướng tới tự động hợp tác giữa các agents. Sử dụng kỹ thuật inception prompting để dẫn dắt hội thoại theo mục tiêu của con người. Ngoài ra, CAMEL cũng là công cụ nghiên cứu hành vi hội thoại giữa các agents. -
AutoGen (Wu et al., 2023a):
Framework linh hoạt, hỗ trợ lập trình agents bằng cả ngôn ngữ tự nhiên và code. Hữu ích cho nhiều lĩnh vực: từ kỹ thuật (code/math) đến giải trí. Điểm mạnh là tuỳ biến cao và dễ mở rộng.
Ngoài ra:
- Chen et al. (2023) giới thiệu các framework mới cho tương tác đa-agents động.
- Zhou, Li, Xie et al. (2023) công bố các thư viện/platforms giúp xây dựng agents tự trị, thích ứng tốt với tác vụ và mô phỏng xã hội.
4.2 Datasets and Benchmarks (Dữ liệu và bộ đánh giá chuẩn)
Mục tiêu sử dụng benchmark khác nhau tùy kịch bản:
-
Problem-Solving:
Dùng để đo năng lực lập kế hoạch và suy luận của các agents khi hợp tác hoặc tranh luận. -
World Simulation:
Đánh giá mức độ phù hợp giữa thế giới mô phỏng và thực tế, hoặc phân tích hành vi agents. -
Khoảng trống:
Các miền như Science Team cho thí nghiệm, mô hình kinh tế, hay giả lập dịch bệnh vẫn còn thiếu bộ benchmark toàn diện. Phát triển chúng sẽ giúp chuẩn hoá việc đo lường hiệu quả LLM-MA.
5. Challenges and Opportunities (Thách thức & Cơ hội)
5.1 Multi-modal Environments (Môi trường đa phương thức)
Phần lớn nghiên cứu LLM-MA hiện nay tập trung vào text-based environments. Tuy nhiên, việc mở rộng sang môi trường đa phương thức (âm thanh, hình ảnh, hành động vật lý) là thách thức lớn:
- Làm sao để agents hiểu và phản hồi đúng với nhiều loại dữ liệu đầu vào/ra khác nhau?
- Làm sao để phối hợp hiệu quả khi không chỉ dựa trên văn bản?
5.2 Hallucination (Ảo giác thông tin)
Vấn đề hallucination (sinh ra nội dung sai) vốn đã phức tạp với LLM đơn lẻ, thì càng nguy hiểm hơn trong hệ multi-agents:
- Một agent hallucinate → thông tin sai lan truyền qua hệ thống.
- Giải pháp cần: phát hiện sớm, ngăn lan truyền, và thiết kế cơ chế kiểm chứng chéo giữa agents.
5.3 Collective Intelligence (Trí tuệ tập thể)
Khác với hệ multi-agent truyền thống (học từ dữ liệu offline), LLM-MA thường học qua tương tác trực tiếp (online feedback).
- Việc xây dựng môi trường tương tác đáng tin cậy là khó.
- Các kỹ thuật như Memory và Self-Evolution hiện nay mới chủ yếu giúp agent đơn lẻ thích nghi, chưa khai thác hết trí tuệ tập thể.
- Cần nghiên cứu cách điều chỉnh đồng thời nhiều agents để tối ưu sức mạnh tập thể.
5.4 Scaling Up (Mở rộng hệ thống)
Việc mở rộng số lượng agents gặp nhiều rào cản:
- Mỗi agent (dựa trên LLM như GPT-4) cần tài nguyên lớn (tính toán, bộ nhớ).
- Số lượng tăng → chi phí tăng → cần chiến lược phối hợp & giao tiếp hiệu quả.
- Cần phát triển kỹ thuật Orchestration tiên tiến (tối ưu task assignment, điều tiết message flow, giảm trùng lặp xung đột).
- Một hướng nghiên cứu mới: xác định scaling laws cho hệ LLM-MA.
5.5 Evaluation & Benchmarks (Đánh giá và Chuẩn hoá)
Hai thách thức lớn:
- Đánh giá hiện tại thường tập trung vào từng agent đơn lẻ → bỏ qua hành vi tập thể quan trọng trong LLM-MA.
- Thiếu benchmark toàn diện cho các lĩnh vực như:
- Điều hành nhóm nghiên cứu khoa học
- Mô hình hoá kinh tế
- Mô phỏng dịch bệnh, đô thị…
Giải pháp: phát triển các bộ test đặc thù, đo được các hành vi nổi bật chỉ xuất hiện khi có sự tương tác giữa nhiều agents.
5.5 Applications and Theoretical Perspectives (Ứng dụng và hướng tiếp cận lý thuyết)
LLM-MA có tiềm năng vượt xa hiện tại:
- Ứng dụng vào: tài chính, giáo dục, y tế, môi trường, quy hoạch đô thị…
- Dù role-playing của LLM hiện còn giới hạn, nhưng tiến bộ nhanh sẽ mở rộng khả năng rất lớn.
Ngoài kỹ thuật, có thể tiếp cận LLM-MA theo các hướng lý thuyết:
- Khoa học nhận thức (Cognitive Science)
- Trí tuệ nhân tạo biểu tượng (Symbolic AI)
- Hệ thống phức tạp (Complex Systems)
- Cybernetics và Trí tuệ tập thể (Collective Intelligence)
Các hướng tiếp cận này hứa hẹn mở ra mô hình mới, sâu sắc và đột phá hơn.
7. Kết luận (Conclusion)
Hệ thống LLM-based Multi-Agents (LLM-MA) đang thể hiện tiềm năng đầy hứa hẹn trong việc hình thành trí tuệ tập thể (collective intelligence), và nhanh chóng thu hút sự quan tâm mạnh mẽ từ cộng đồng nghiên cứu.
Khảo sát này đã hệ thống hóa sự phát triển của LLM-MA qua các góc nhìn:
- Tương tác giữa agents và môi trường
- Đặc trưng hóa agents thông qua LLMs
- Chiến lược điều phối giao tiếp giữa các agents
- Các mô hình tiếp thu và nâng cấp năng lực tác vụ
Bên cạnh đó, bài viết đã tổng hợp các ứng dụng thực tiễn trong giải quyết vấn đề và mô phỏng thế giới, đồng thời trình bày bộ dữ liệu, benchmark phổ biến, cũng như những thách thức và cơ hội đang mở ra cho lĩnh vực này.
Với cấu trúc toàn diện và định hướng rõ ràng, chúng tôi kỳ vọng bản khảo sát này sẽ là tài liệu tham khảo hữu ích cho các nhà nghiên cứu ở nhiều lĩnh vực khác nhau, đồng thời truyền cảm hứng cho các hướng nghiên cứu mới, nhằm khai thác tối đa tiềm năng của hệ thống LLM-MA trong tương lai.
Tiếp theo:
- http://mikesholic.com/knowledgeai/2025/10/12/AI_Agentic_Summary.html
- http://mikesholic.com/knowledgeai/2025/10/12/Challenges-AI-Agent.html
- http://mikesholic.com/knowledgeai/2025/10/12/Challenges-Agentic-AI.html
- http://mikesholic.com/knowledgeai/2025/10/12/Solution-AI-Agent-Agentic.html